Umělá inteligence přichází na scénu – nejprve pomalu a pak okamžitě, jako by k nám letěla mimozemská loď rychlostí blízkou rychlosti světla. Po většinu délky letu ji nevidíme, pak se něco objeví, ale než tuto informaci zpracujeme, už je to tady. V posledních měsících se objevilo několik revolučních modelů umělé inteligence, o kterých si povíme, ale začněme nejprve krátkou historickou mezihrou.

i
Článek reprezentuje názor autora, nikoliv Alza.cz.
Umělá inteligence k nám přišla ve vlnách – první vlna začala v 50. letech 20. století, kdy první průkopníci umělé inteligence, jako například Alan Turing a Marvin Minsky, začali rozvíjet základní koncepty výzkumu umělé inteligence. Převládajícím přístupem v tomto období byl symbolický přístup nebo přístup založený na pravidlech, který se zaměřoval na používání symbolů a logických pravidel na reprezentaci znalostí a provádění uvažování. Příkladem tohoto přístupu byly expertní systémy založené na inferenci poznatků z faktů a pravidel. Například: „pokud Alice a Bob zplodili malého Charlieho, Charlie je chlapec, Charlie se narodil živý => Alice má syna Charlieho a Bob má syna Charlieho”.
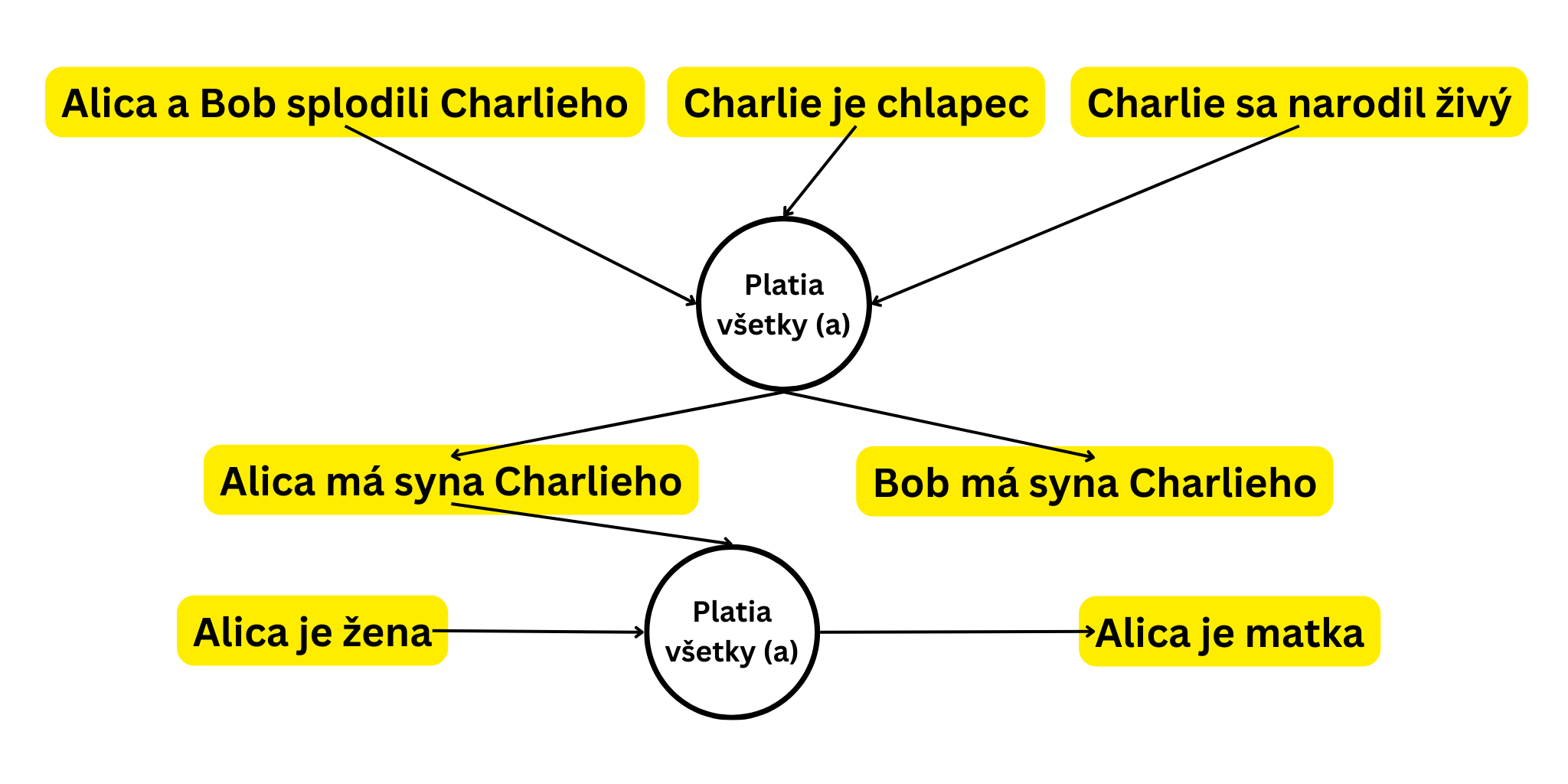
Reprezentace podle pravidel, která definují vztahy, naráží na limity vypočitatelnosti a možnosti reprezentace všech vztahů ve světě. Komplexní svět je obtížné popsat dokonce i velkým množstvím pravidel – dokonce tak obtížné, že si momentálně myslíme, že je to nemožné. To je mimochodem i jeden z důvodů, proč nefunguje centrální plánování.
O „nemožné“ se však snažilo několik projektů, například projekt Cyc a jeho otevřená verze OpenCyc, která už však není vyvíjena. Ze současných projektů, které pracují na bázi symbolové umělé inteligence, vzpomeňme projekt WolframAlpha, který dokáže odpovědět na poměrně sofistikované otázky pomocí symbolických výpočtů.
Druhým důvodem nefunkčnosti centrálního plánování i symbolové umělé inteligence v komplexním světě je to, že není možné získat informace o světě, zejména proto, že většina informací existuje až v době rozhodnutí, tedy v době inference, kdy čas pokročí. Mohu říci, že mám chuť na pomeranč, ale podstatné je, když si ho koupím (nebo vypěstuji), oloupu a sním – tato informace tedy vznikne až tehdy, když není až tak užitečná pro inferenci, tedy pro zjištění toho, zda má někdo vypěstovat pomeranč.
Symbolová umělá inteligence má však jednu základní výhodu oproti konekcionistickým modelům – a to, že dokáže vysvětlit, proč dospěla k danému závěru. Jednoduchým jmenováním aplikovaných pravidel. To je něco, co momentální modely umělé inteligence nedokážou.
První model perceptronu – který je základní jednotkou neuronové sítě – vymyslel Frank Rosenblatt v roce 1957 v paperu „The Perceptron: Perceiving and Recognizing Automaton“.

Rosenblatt potom v roce 1962 publikoval knihu „Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms“, která rozšířila a rozpracovala jeho původní myšlenky a teorie o perceptronech.
Perceptron si můžeme představit jako jednoduchou jednotku, která zpracovává informace. Skládá se ze vstupů, vah a součtu měřených vstupů a aktivační funkce. Jelikož se jedná o velmi jednoduchý model, pojďme si ho představit:
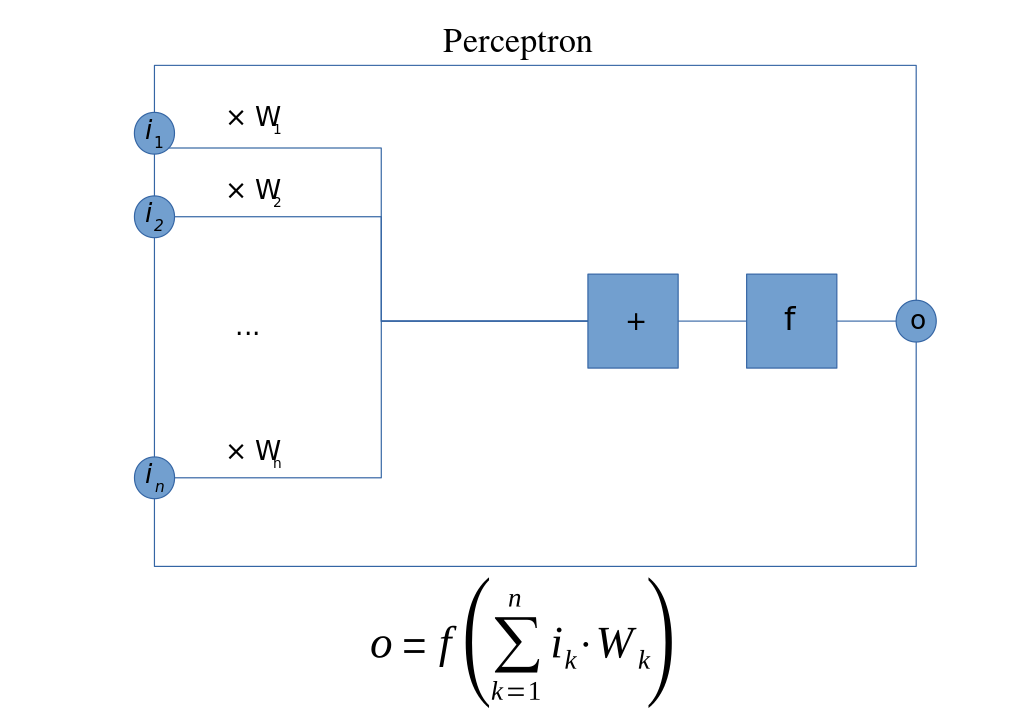
Vstupy: Perceptron má několik vstupů, podobně jako neurony v našem mozku. Každý vstup je spojen s určitou hodnotou a váhou, která určuje, jak je daný vstup důležitý. Můžeme to chápat tak, že některé informace jsou pro určitý úkol důležitější než jiné. Například, pokud bychom chtěli určit, jestli bude za hodinu pěkný letní den, teplota je důležitější informace než například barva oblohy.
Součet zvažovaných vstupů: váhy jsou pak násobeny jejich příslušnými vstupy a výsledky jsou sečteny do jednoho čísla. To je, jako kdybyste udělali seznam pro a proti při rozhodování, kde každý bod pro i proti má určitý význam nebo váhu.
Aktivační funkce: výsledek se pak porovná s nějakým prahem (threshold) pomocí aktivační funkce. Pokud je výsledek nad tímto prahem, perceptron vyprodukuje jednu hodnotu (například 1), v opačném případě vyprodukuje jinou hodnotu (například 0). Je to jako rozhodnutí, které učiníte na základě seznamu vážených pro a proti.
Důležitým pojmem v umělé inteligenci je „učení“ – perceptron se učí tak, že hledá váhy, které nejlépe vyřeší problém. Například pokud pro nějaké vstupy známe správné výstupy (máme příklady), můžeme vyzkoušet výpočet a zjistit, jestli perceptron dal správný výsledek. Pokud se zmýlil, tak probíhá učení pomocí tzv. zpětného šíření chyby. Podíváme se, o kolik se spletl, a které váhy na tom mají jakou zásluhu. Algoritmus zpětného šíření chyby neboli backpropagation je jedním z nejčastěji používaných algoritmů učení.
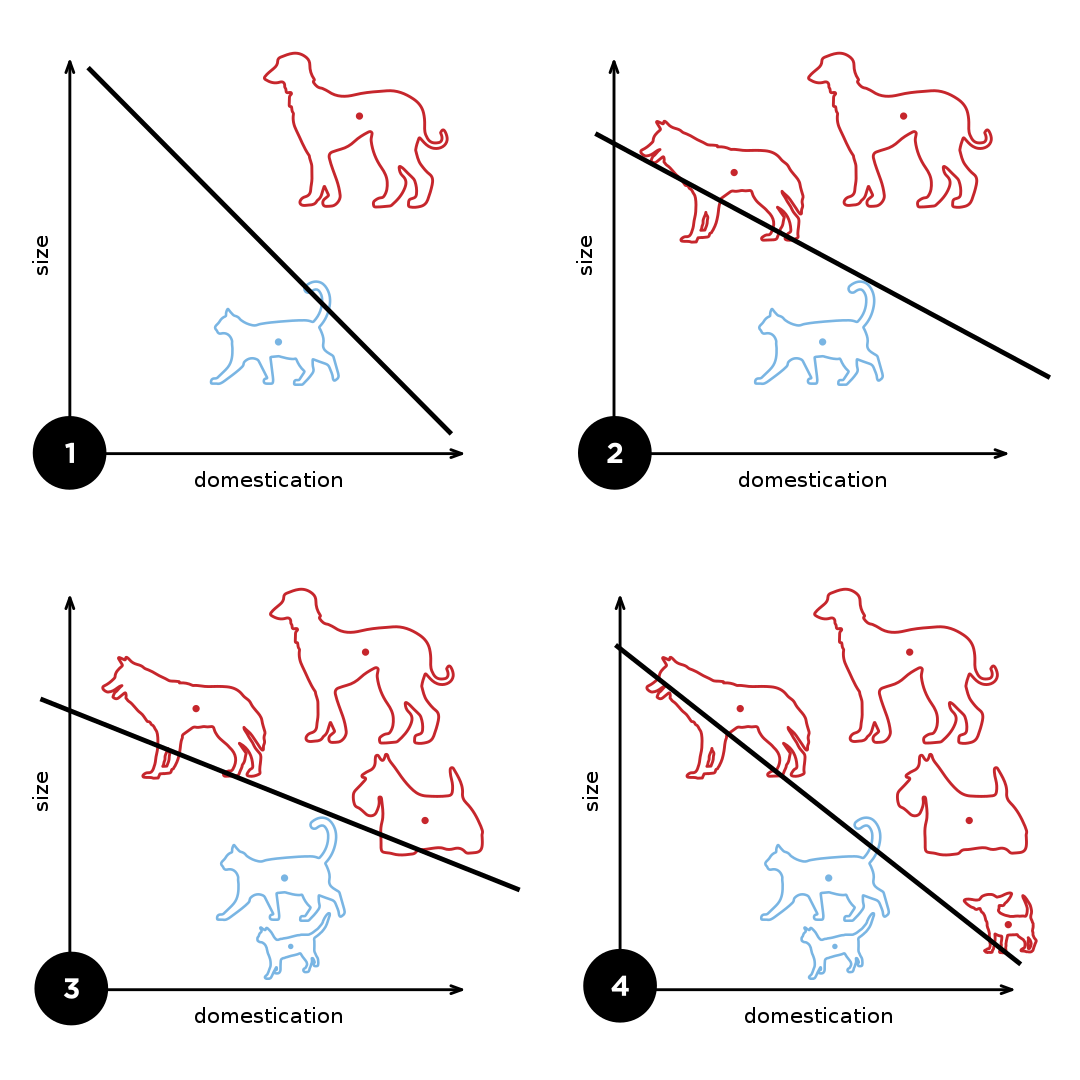
Na obrázku máme na začátku jednoho psa a jednu kočku. Jelikož popisuje lineární funkci, hledá ve skutečnosti čáru, která odděluje dva typy příkladů. Pokud má pouze dva příklady, může například najít čáru na první části obrázku, která funguje. Přidáním dalšího psa do trénovací množiny musí čáru upravit, protože původní čára by psa označila za kočku. Jak přidáváme další příklady do učící množiny, čára se upravuje. Může se však stát, že čára nám neumožní oddělit příklady a je zapotřebí složitější funkce, která umožní popsat nelineární hranici mezi příklady.
Toto omezení popsali Marvin Minsky a Seymour Papert ve své knize „Perceptrons: an introduction to computational geometry“. Perceptron dokáže řešit jen ty úkoly, které jsou lineárně separovatelné, to znamená, že existuje rovina (nebo přímo čára), která dokáže oddělit data do různých kategorií. Asi nejjednodušší příklad, který nelze lineárně separovat, je booleovská funkce XOR.
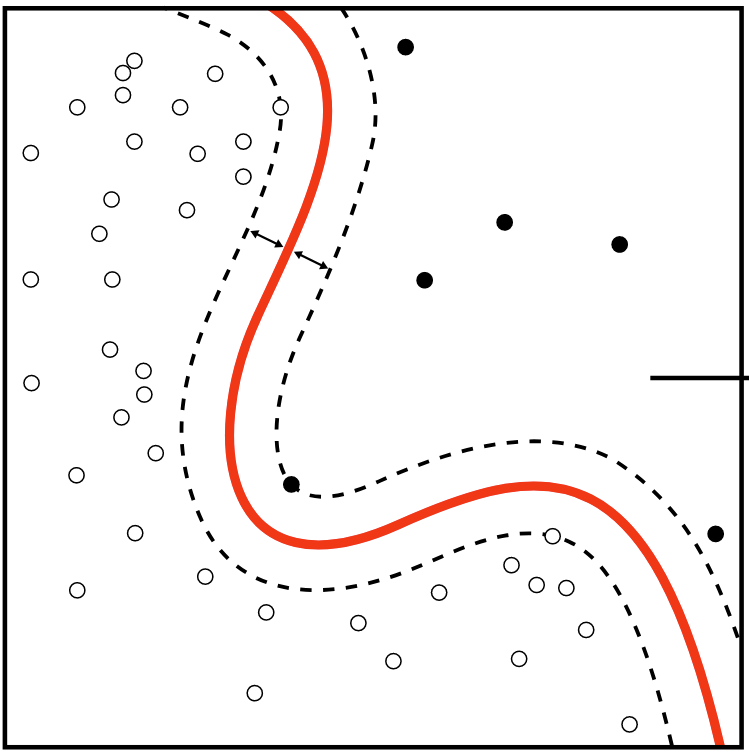
To je jeden z důvodů, proč se dnes používají sofistikovanější neuronové sítě, které dokáží řešit i složitější, nikoli lineární úkoly.
Alan Turing definoval test inteligence pomocí „imitační hry“ v chatovacím rozhraní (dnes ho známe jako Turingův test). Test byl představen v článku „Computing Machinery and Intelligence“ z roku 1950. Nejsme-li schopni spolehlivě odlišit v chatovacím rozhraní člověka od stroje, prošel stroj testem inteligence a říkáme, že stroj má jistou formu umělé inteligence „na úrovni člověka“. Kritici říkají, že inteligence v chatovacím okénku není komplexním projevem inteligence člověka – schopnost úspěšně napodobit lidské chování není podle nich stejná jako skutečné pochopení nebo vědomí. Někdy po čtení flamewarů na sociálních sítích tomu začínám věřit.

Minského a Papertova práce na perceptronech, jednoduchých neuronových sítích, a následná omezení, na která upozornil, vedly ke skepsi vůči potenciálu neuronových sítí až do začátku druhé vlny umělé inteligence v 80. a 90. letech.
Druhá vlna se nesla ve znamení zaměření pozornosti na konekcionistické modely a neuronové sítě, které byly inspirovány biologickými neuronovými sítěmi. Výzkum směřoval k lepším algoritmům učení, znovuobjevení algoritmu zpětného šíření chyby (backpropagation), která umožnila neuronovým sítím učit se z dat. Výzkum byl však omezen možnostmi výpočetní síly a dostupnosti trénovacích dat.
Třetí vlna začala v roce 2010 a trvá dodnes. Nastala díky konvergenci zvýšeného množství dat (často označených), výpočetní kapacity a nových architektur neuronových sítí (konvoluční neuronové sítě, rekurentní neuronové sítě a transformery). Díky zvýšené výpočetní a paměťové kapacitě lze natrénovat neuronové sítě s velkým množstvím vrstev a neuronů (takové sítě označujeme jako „deep“, tedy hluboké, což odkazuje na množství vrstev). Data poskytl Internet – roboty prohledávané a indexované webové stránky, ale také označené datasety, jako například ImageNet, kde lidé popisovali obrázky (kočička na stole, tančící bobr atd). Konvergence těchto událostí a množství času lidí spustila revoluci. ImageNet měl 12 milionů obrázků, které byly popsány na základě ontologie WordNet. Pokud by měl data anotovat jeden člověk rychlostí jeden obrázek za minutu a nedělal by nic jiného (včetně spánku nebo jídla), trvalo by mu to 22 let a 10 měsíců.
Výsledkem kombinace těchto inovací a technologického pokroku byly obrázkové modely jako Stable Diffusion (a DALL-E či MidJourney), které umožňují vytvoření obrázků z textového popisu, chatovací rozhraní velkých jazykových modelů, jako například ChatGPT, Bing či Bard.
Asi nejzajímavější část je však open-source inovace. To si uvědomili i v Googlu, alespoň pokud je pravý tento uniklý dokument. Stable Diffusion je open-source model pro generování obrázků, který spustil obrovskou sadu inovací. Lidé začali trénovat a zveřejňovat tvz. „fine-tuned“ modely – s použitím základního modelu vylepšily neuronovou síť za jedno odpoledne tak, že generuje například lepší portréty, manga postavičky nebo mé oblíbené synthwave obrázky. Tyto programy můžete nechat běžet na vlastním počítači – buď s dostatečně silnou grafickou kartou, nebo na moderním hardwaru s akcelerací na neuronové sítě, například na zařízeních Apple s novými Apple Silicon procesory (přitom je jedno, zda se jedná o iPhone nebo MacBook Pro).
Podobná inovace nastala i u jazykových modelů. Přestože existovalo poměrně velké množství volně dostupných jazykových modelů, jako například Bloom, FLAN, Pytia, či množství jiných, revoluci přinesl model LLaMA od Meta (bývalý Facebook). Tento model přichází ve více variantách, od nejmenšího se 7 miliardami parametrů až po 65 miliardový model. Číslo uvádí počet trénovatelných parametrů a zároveň určuje, jak silný hardware potřebujete pro jeho běh. V 8bitové přesnosti potřebujete na 7 miliardový model cca 7GB RAM, což se vejde do RAM většiny grafických karet, a dokonce i mobilních zařízení. 13 miliardový model už má smysl srovnávat s ChatGPT. Vysoká kvalita i přes malé množství parametrů byla jedna z inovací tohoto modelu.
Zajímavé však bylo, že na rozdíl od mnoha jiných modelů tento model nebyl uvolněn pod open-source licencí. Paper, kód na trénování, byl sice zveřejněn, ale natrénované váhy (tedy to, co je výsledkem drahého trénovacího procesu) byl zpřístupněn jen vybraným výzkumníkům a jen k nekomerčním účelům. Brzy se však na githubu projektu objevila mezi „issues“ magnet linka na torrent, která obsahovala všechny váhy, s informací, že přece není dobré zatěžovat takovým datovým tokem servery Facebooku. Později se model objevil také na portálu Hugging Face, což je takový „github pro AI modely a datasety“. Meta proti tomuto zveřejnění nezakročila, ale stále se tváří, že model je pouze pro nekomerční použití.
Co se stalo potom, je však úžasné a ukazuje to sílu open-source komunity. A o tom je i leaknutý dokument z Google. Tento model spustil šílenou vlnu inovací.
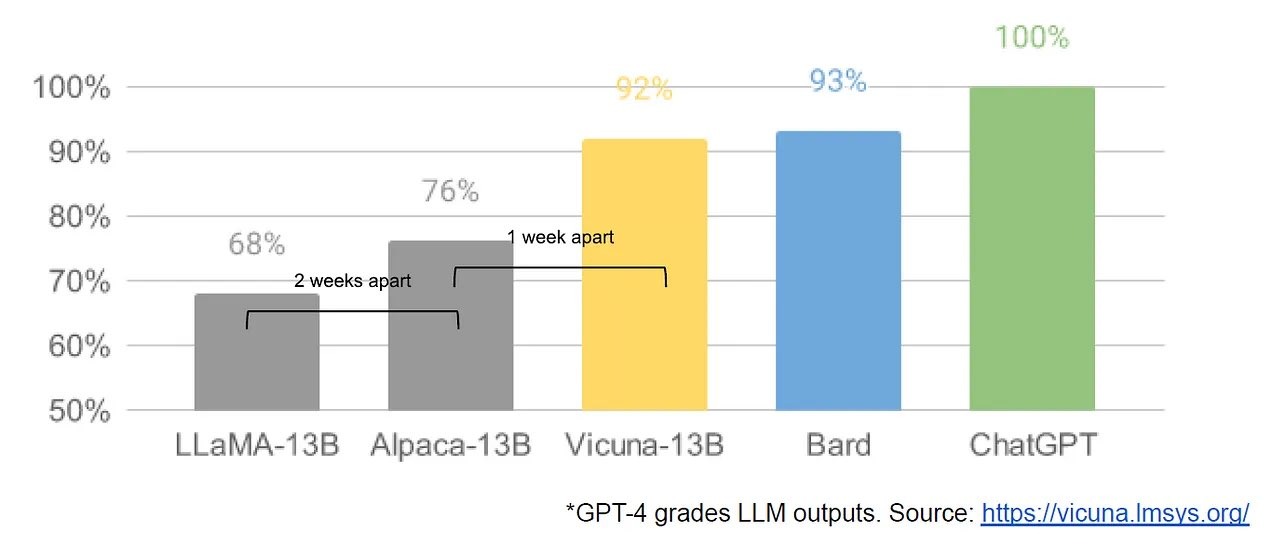
Původní verze LLaMA byla natrénována pouze na textovém datasetu. Uměla „pokračovat v textu“, neuměla tedy následovat instrukce nebo být přímo součástí nějakého rozhovoru. Cca na takové úrovni byl model GPT-3 od OpenAI (se 165 miliardami parametrů). Pouze o dva týdny později vznikla z LLaMA-13B Alpaca-13B, která už uměla následovat instrukce. Dotrénování pomocí technologie LoRA (Low Rank Adaptation) stálo autory ze Stanfordské univerzity 600 USD ve výpočetní kapacitě. Uvolněný trénovací dataset, který vznikl pomocí interakcí s ChatGPT přes API, použili další lidé k dotrénování a uvolnění vah. O týden později vznikl dataset Vicuna-13B, který už má smysl srovnávat s ChatGPT. Má klasický konverzační interface, jaký znáte z ChatGPT. Ale hlavní rozdíl je, že je vytvořen dotrénováním mimo obrovské korporátní struktury (i když samozřejmě většinu nákladů zaplatila Meta trénováním hlavního modelu). A dokážete ho rozběhnout na vlastním zařízení, aniž byste někomu museli něco posílat.
Postupně začaly vznikat další modely a datasety – Dolly, Baize, StableLM, OpenAssistant atd. Dnes jsme ve stavu, kdy si každý může lokálně dotrénovat vlastní model. Máte právnickou kancelář a chtěli byste pomoci se psaním smluv? Nebo potřebujete rozřešit případ na základě předchozích soudních rozhodnutí? Jste lékař a potřebujete rozhraní, které vám ukáže něco, co jste možná zanedbali a neověřili? Postupně začínají vznikat i tvz. multimodální modely, které dokáží propojovat obraz, zvuk a text. Pomohou vám s programováním.
I když není tak snadné vytvořit model podobný ChatGPT pro obrovské počáteční náklady, budoucnost možná bude v dolaďování dostupných modelů. Dolaďování lze kombinovat a možná budeme spíše „doučovat“ stávající modely. To neznamená, že inovace v základních modelech se zastaví. Stability AI trénuje jejich nové StabilityLM modely, mnohé další organizace pracují na nových open-source jazykových modelech. Také vznikají nové verze Stable Diffusion. Jedním z hlavních důvodů je problém s nejasnou licencí modelu LLaMA.
Jednou z nesčetného množství výhod těchto otevřených modelů je, že mohou běžet na koncových zařízeních. V prostředí, kde není bezpečné uploadovat citlivá data do cloudu nebo není dostupná dostatečná internetová konektivita.
A v tomto světě se nacházíme. Rozvoj je tak rychlý, že od doby, kdy píšu tyto řádky, do doby, kdy je článek zveřejněn a dostal se k vám, pravděpodobně proběhl šílený vývoj. A to je dobře.
První a druhá vlna představovaly larvální stádium umělé inteligence a naznačovaly budoucí metamorfózu. Nyní se tato digitální kukla otevřela a vynořil se z ní nádherný motýl s neomezeným potenciálem. Toto není konec, ale krásný úsvit nejvíce transformační a nejzajímavější éry umělé inteligence. A na ni se podíváme v dalších dílech seriálu.

Juraj Bednár
Jsem cypherpunker, mám rád svobodu, soukromí, peer to peer technologie a terminálová okna. Zkoumám chaotický svět, volatilitu a nejistotu, bojuji proti entropii - zakládám firmy a neziskové projekty, dělám kurzy a píšu knihy. Jsem spoluzakladatel Paralelní Polis, hackerspace Progressbar a bug bounty platformy Hacktrophy. Vystudoval jsem obor umělá inteligence a ta se vrátila tak, jako bych o ni nikdy ani neslyšel. O všech těchto zkušenostech píšu blog.
